Optimisation des coûts Kubernetes sur Google Cloud Platform

Dans un contexte où le cloud computing devient une norme, optimiser les coûts liés aux infrastructures Kubernetes est un enjeu de taille pour les équipes DevOps. Sur Google Cloud Platform (GCP), GKE (Google Kubernetes Engine) offre des outils avancés pour gérer et orchestrer les clusters, mais savoir configurer et optimiser ces outils est essentiel pour maîtriser les dépenses sans sacrifier la performance.
Dans cet article, nous allons explorer plusieurs stratégies avancées et actionnables pour réduire les coûts des clusters Kubernetes sur GCP. Ces pratiques, basées sur une gestion efficace des ressources et l’automatisation des workflows, permettront aux équipes d’améliorer la rentabilité de leurs clusters Kubernetes.
1. Utiliser les bons types de nœuds et de machines
1.1 Comparer les options : machines standard, préemptibles, spot et custom
Pour chaque workload, il est crucial de sélectionner le bon type de machine. GCP propose des VM standard, des Preemptible VMs (VM préemptibles), des Spot VMs (VM spot), et des Custom Machine Types qui permettent d’adapter les ressources aux besoins spécifiques de chaque workload.
-
VM Standard: Ce sont les machines par défaut, stables et durables, idéales pour les applications critiques et les charges de travail qui nécessitent une disponibilité constante. Cependant, elles coûtent plus cher que les options préemptibles ou spot. Elles sont recommandées pour des services en production qui ne peuvent pas être interrompus. -
Preemptible VMs: Les Preemptible VMs sont des instances temporaires qui peuvent être interrompues par GCP lorsque les ressources sont nécessaires ailleurs. Elles sont bien moins chères que les VM standard, mais sont limitées à un temps de vie maximal de 24 heures. Ces VM sont idéales pour les tâches non critiques ou les traitements batch. Ce type de machine ne doit plus être utilisé pour de nouveaux usages au profit desspot. -
Spot VMs: Introduites plus récemment que les Preemptible VMs, les Spot VMs offrent un modèle de coût similaire mais avec une flexibilité accrue. Elles ne sont pas limitées par une durée de vie de 24 heures et peuvent durer jusqu'à ce que GCP ait besoin des ressources. Elles sont parfaites pour les charges de travail temporaires, à faible priorité et sans état. Cas d'utilisation : Si vous avez des tâches de machine learning non critiques ou des pipelines ETL qui peuvent être relancés, les Spot VMs sont une excellente option pour réduire les coûts. -
Custom Machine Types: Les Custom Machine Types permettent de spécifier exactement le nombre de vCPU et la quantité de RAM pour correspondre aux besoins précis de chaque workload. Contrairement aux types de machines prédéfinis, cette flexibilité permet d’éviter le gaspillage de ressources. Exemple d’optimisation : Si votre application a besoin de beaucoup de mémoire mais peu de CPU, une machine custom avec 2 vCPU et 16 Go de RAM pourrait réduire les coûts en comparaison à une machine préconfigurée qui offre un rapport CPU/RAM trop élevé.
1.2 Exploiter les node pools optimisés
Utilisez des pools de nœuds distincts dans GKE pour assigner des VM standard, préemptibles, et spot selon les besoins des workloads. Cela permet de mixer différents types de machines au sein d’un même cluster et d'optimiser l'allocation des ressources. Par exemple, configurez un pool avec des Preemptible VMs pour les tâches non critiques et un autre pool standard pour les workloads essentiels.
En configurant plusieurs node pools au sein d’un cluster GKE, vous pouvez segmenter vos charges de travail par type de ressource et criticité. Cette approche permet une meilleure maîtrise des coûts et une optimisation de la performance pour chaque type de workload.
Exemple de node pools optimisés :
-
node pool de production avec VM standard : Destiné aux applications critiques, ce pool garantit la stabilité et la disponibilité. Configurez-le avec des machines standard pour éviter toute interruption.
-
node pool de traitement batch avec Spot VMs : Utilisez des Spot VMs pour des tâches sans état ou des traitements batch à faible priorité, comme le calcul d’analyses ou l'entraînement de modèles de machine learning non critiques. Les environnements de développement ou de test peuvent être configurés avec des Spot VMs pour réduire les coûts. Étant donné que ces environnements ne nécessitent pas une disponibilité continue, le risque d'interruption est tolérable.
Cas d’usage avancé : Pour les applications modernes qui utilisent une architecture de microservices, vous pouvez assigner des Node pools différents à chaque microservice en fonction de ses besoins spécifiques. Par exemple, un microservice qui doit gérer des requêtes en temps réel pourrait être sur un Node Pool de machines standard, tandis qu’un microservice qui effectue des tâches de fond pourrait être hébergé sur des VM spot.
2. Utiliser les VM spot en production
L’utilisation des VM spot (ou VM préemptibles dans leur version initiale) en production peut sembler risquée en raison de leur caractère temporaire : ces instances peuvent être interrompues par Google Cloud lorsqu’il a besoin des ressources, et leur disponibilité n'est jamais garantie. Cependant, avec une configuration adaptée et en tirant parti des fonctionnalités avancées de Kubernetes, les VM spot peuvent réellement contribuer à réduire les coûts, même pour des charges de travail en production, à condition de bien gérer les risques d'interruption.
Il est essentiel de connaître les limitations techniques des VM spot avant de les intégrer en production, notamment en ce qui concerne leur interruption soudaine par Google Cloud. Lorsqu'une VM spot doit être récupérée par GCP pour d'autres usages, elle est interrompue avec un préavis de seulement 30 secondes. Durant cette période, toutes les applications en cours doivent gérer l’arrêt et s’arrêter proprement si possible. Dans l'idéal, la charge de travail devrit s'arrêter en moins de 15 secondes.
Voici quelques stratégies pour intégrer les VM spot dans des environnements de production sans compromettre la fiabilité des services :
Stratégie 1 : Utiliser les VM spot pour les workloads sans état (stateless)
Les applications sans état sont idéales pour les VM spot, car elles peuvent tolérer des interruptions temporaires sans perdre de données ou affecter la continuité du service. Les exemples de workloads sans état incluent les serveurs web, les microservices de gestion de sessions utilisateur, et les instances de cache temporaire.
- Exemple d’implémentation : Configurez les pods sans état dans des Node Pools utilisant des VM spot. Si un pod est interrompu, Kubernetes le redéploye automatiquement sur une autre VM disponible. Cette approche permet de maintenir un niveau de service constant, tout en réduisant les coûts d’infrastructure.
Stratégie 2 : Combiner les VM spot avec des VM standard pour garantir une continuité de service
Pour des workloads critiques ou semi-critiques, où une interruption totale serait inacceptable, il est possible de combiner des VM spot et des VM standard dans un même cluster. Cela permet de bénéficier de la réduction de coût offerte par les VM spot, tout en garantissant la continuité de service en cas d’interruption.
-
Configuration du Node Pool hybride : Créez un Node Pool mixte contenant des VM standard et des VM spot. Configurez les pods critiques pour être toujours répartis sur les VM standard, tandis que les workloads moins critiques peuvent tourner sur des VM spot.
-
Exemple d’usage : Dans une application e-commerce, vous pourriez déployer les services critiques (comme les services de paiement ou d’authentification) sur des VM standard, tandis que les services non essentiels (comme le traitement de recommandations ou la gestion d'inventaire en temps réel) peuvent fonctionner sur des VM spot. En cas d'interruption, seuls les services non essentiels seront temporairement affectés.
Stratégie 3 : Exploiter les StatefulSets pour des workloads avec une tolérance de panne
Dans certains cas, même des workloads ayant besoin de stocker des données peuvent être exécutés sur des VM spot, si une redondance de données et une tolérance de panne sont configurées. Les StatefulSets permettent de garantir l'ordre de démarrage des pods, leur persistance, et leur résilience aux interruptions. Pour des workloads qui nécessitent une continuité, mais peuvent accepter une tolérance limitée aux pannes, il est possible d’exploiter les StatefulSets en association avec les VM spot.
- Exemple de cas d'usage : Pour une base de données NoSQL distribuée (comme Cassandra ou Elasticsearch), déployez plusieurs réplicas sur un ensemble de VM spot, tout en configurant des StatefulSets pour gérer l’ordonnancement des pods. Cela permet d’assurer qu’en cas de perte de quelques VM spot, les réplicas restants continuent à fonctionner, maintenant ainsi une disponibilité globale.
3. Autoscaling horizontal et vertical
Le Horizontal Pod Autoscaler (HPA) et le Vertical Pod Autoscaler (VPA) sont deux outils puissants pour ajuster les ressources en fonction des besoins.
-
Horizontal Pod Autoscaler (HPA) : Redimensionne automatiquement le nombre de pods en fonction de la charge (CPU, utilisation de la mémoire). Exemple : Si votre application subit des pics de trafic, HPA peut augmenter le nombre de pods, puis les réduire quand la charge diminue, permettant ainsi de ne pas surprovisionner en dehors des périodes de pic.
-
Vertical Pod Autoscaler (VPA) : Ajuste automatiquement la mémoire et le CPU alloués à chaque pod. Pour les applications dont la charge fluctue de manière imprévisible, cela permet d’éviter des défaillances par manque de ressources ou des gaspillages par excès de provisionnement.
Astuce : Utilisez HPA et VPA conjointement pour des résultats optimaux. En configurant HPA pour gérer les variations de trafic et VPA pour optimiser les ressources de chaque pod, vous pouvez créer une architecture hautement performante et économique.
4. Déploiement d'un cluster GKE optimisé pour les coûts
Dans cette section, nous allons montrer comment déployer un cluster Kubernetes sur GCP, avec Terraform, en utilisant une architecture de Node Pools optimisée pour les coûts et la résilience. Nous allons configurer un cluster avec trois types de Node Pools, chacun destiné à des types de charges de travail spécifiques, en prenant en compte les VM spot et on-demand, ainsi que des règles d'affinité pour garantir l'usage prioritaire des VM spot.
Objectif
Le but de cette configuration est d'assurer une répartition des workloads entre les VM spot et les VM on-demand. Nous allons configurer :
- Un Node Pool de VM spot N2 pour les workloads pouvant tolérer des interruptions.
- Un Node Pool de VM spot E2 pour les workloads pouvant tolérer des interruptions. On rajoute un second node pool avec des machines différentes pour maximiser les chances d' provisionner une VM spot si les N2 spot sont en rupture.
- Un Node Pool de VM on-demand N2 pour garantir la continuité des services en production, en cas d’indisponibilité des VM spot.
Prérequis
Avant de commencer, assurez-vous d’avoir installé :
- Terraform
- Un projet Google Cloud configuré, avec l'API GKE activée
- Des informations d'identification GCP pour permettre à Terraform d'accéder à votre compte
Exemple de code Terraform
Le code Terraform ci-dessous déploie un cluster GKE avec trois node pools. Nous allons utiliser des règles d'affinité (affinity) pour que les pods préfèrent les nœuds spot mais puissent basculer vers des nœuds on-demand en cas d’indisponibilité.
# Terraform block pour configurer le provider GCP
provider "google" {
project = var.project_id
region = var.region
}
# Ressource pour créer un cluster GKE
resource "google_container_cluster" "primary" {
name = "cost-optimized-gke-cluster"
location = var.region
initial_node_count = 1 # Nombre initial minimal pour le cluster
# Configurer le master du cluster
remove_default_node_pool = true
network = var.network
subnetwork = var.subnetwork
# Activer l'autoscaling au niveau du cluster
autoscaling {
enabled = true
}
}
# Node Pool 1 : Node Pool avec VM Spot N2
resource "google_container_node_pool" "spot_n2_pool" {
cluster = google_container_cluster.primary.name
location = var.region
name = "spot-n2-pool"
# Configuration des VM Spot N2
node_config {
machine_type = "n2-standard-4"
spot = true # Indiquer que ces nœuds sont des VM spot
oauth_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
}
# Configurer l'autoscaling
autoscaling {
min_node_count = 1
max_node_count = 10
}
# Taints et labels pour identifier les nœuds spot
node_config {
labels = {
spot = "true"
type = "n2"
}
}
}
# Node Pool 2 : Node Pool avec VM Spot E2
resource "google_container_node_pool" "spot_e2_pool" {
cluster = google_container_cluster.primary.name
location = var.region
name = "spot-e2-pool"
# Configuration des VM Spot E2
node_config {
machine_type = "e2-standard-4"
spot = true # Indiquer que ces nœuds sont des VM spot
oauth_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
}
# Configurer l'autoscaling
autoscaling {
min_node_count = 1
max_node_count = 5
}
# Taints et labels pour identifier les nœuds spot E2
node_config {
labels = {
spot = "true"
type = "e2"
}
}
}
# Node Pool 3 : Node Pool avec VM On-Demand N2
resource "google_container_node_pool" "on_demand_n2_pool" {
cluster = google_container_cluster.primary.name
location = var.region
name = "on-demand-n2-pool"
# Configuration des VM On-Demand N2
node_config {
machine_type = "n2-standard-4"
spot = false # VM On-Demand
oauth_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
}
# Configurer l'autoscaling
autoscaling {
min_node_count = 1
max_node_count = 5
}
# Taints et labels pour identifier les nœuds on-demand N2
node_config {
labels = {
spot = "false"
type = "n2"
}
}
}
Définir l'affinité des pods
Pour optimiser la répartition des workloads entre VM spot et on-demand, nous allons utiliser une règle d’affinité preferredDuringSchedulingIgnoredDuringExecution. Cette règle configure les pods pour qu'ils soient placés en priorité sur les nœuds spot (tant qu’ils sont disponibles), mais leur permet également de basculer sur des VM on-demand en cas d’indisponibilité des VM spot.
Voici un exemple de configuration YAML Kubernetes à appliquer pour un pod :
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-deployment
spec:
replicas: 3
template:
metadata:
labels:
app: example
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
preference:
matchExpressions:
- key: spot
operator: In
values:
- "true"
- weight: 50
preference:
matchExpressions:
- key: spot
operator: In
values:
- "false"
containers:
- name: example-container
image: nginx
Dans cet exemple :
- La règle
preferredDuringSchedulingIgnoredDuringExecutionapplique un poids de 100 aux nœuds avec l'étiquettespot=true(VM spot) et un poids de 50 aux nœuds avecspot=false(VM on-demand). - Les pods seront donc placés prioritairement sur les nœuds spot, mais pourront être programmés sur les nœuds on-demand en cas d'indisponibilité des nœuds spot, garantissant la continuité de service.
Limite des affinités
Les règles d'affinité permettent de spécifier où les pods doivent être déployés en fonction de certaines caractéristiques des nœuds, comme l’utilisation de VM spot ou on-demand. Cependant, cette méthode présente plusieurs limites en pratique :
-
Affinité
requiredDuringSchedulingIgnoredDuringExecution: Cette règle impose un placement strict. Si un pod est configuré pour exiger un nœud avec une étiquette particulière (par exemple, spot=true), Kubernetes ne déploiera le pod que sur un nœud correspondant. Si aucun nœud spot n’est disponible au moment du déploiement, le pod ne sera pas programmé et restera en attente indéfiniment, compromettant la disponibilité de l'application. -
Affinité
preferredDuringSchedulingIgnoredDuringExecution: Cette option est plus souple et recommande, sans forcer, le placement sur des nœuds spot lorsque c’est possible. Cependant, dans un cluster mixte (spot et on-demand), il arrive fréquemment que des pods soient déployés sur des nœuds on-demand si les nœuds spot sont saturés ou momentanément indisponibles. Dans ce cas, la gestion des coûts devient imprévisible. De plus, il est nécessaire de configurer une logique supplémentaire pour reprogrammer les pods sur des nœuds spot dès qu'ils deviennent disponibles, une tâche souvent complexe à automatiser et gérer.
Ces limites montrent que les règles d'affinité seules ne sont pas idéales pour garantir de manière fiable l'exécution des pods sur des nœuds spot. Heureusement, l’utilisation des Compute Classes GKE simplifie ce processus.
Utilisation des Compute Classes GKE pour exécuter des pods sur des VM Spot
Dans GKE, les Compute Classes permettent de définir des préférences de placement de pods au sein d’un cluster, sans les limitations des règles d'affinité. En créant une Compute Class personnalisée qui privilégie les nœuds spot, les pods configurés pour cette classe seront prioritairement déployés sur des VM spot, tout en bénéficiant d’un fallback automatique vers les VM on-demand si nécessaire.
Exemple de configuration d'une Compute Class personnalisée pour les VM Spot
La configuration suivante crée une Compute Class préférant les VM spot. Cela garantit que les pods ciblés seront prioritairement exécutés sur des nœuds spot :
apiVersion: cloud.google.com/v1
kind: ComputeClass
metadata:
name: spot-preferred
spec:
priorities:
- machineFamily: n2
spot: true
- machineFamily: e2
spot: true
- machineFamily: n2
spot: false
nodePoolAutoCreation:
enabled: true
Ensuite, vous pouvez spécifier cette Compute Class dans les configurations de déploiement de vos workloads :
apiVersion: apps/v1
kind: Deployment
metadata:
name: spot-app-deployment
spec:
replicas: 3
template:
metadata:
labels:
app: spot-app
spec:
nodeSelector:
cloud.google.com/compute-class: "spot-preferred"
containers:
- name: spot-container
image: nginx
Dans cet exemple, la Compute Class spot-preferred indique que les pods doivent être placés de préférence sur des nœuds spot, mais pourront être automatiquement reprogrammés sur des nœuds on-demand si aucun nœud spot n'est disponible. Cela permet de maintenir un coût d’exécution réduit sans compromettre la disponibilité des pods.
Les Compute Classes personnalisées pour privilégier les nœuds spot comportent quelques limites importantes. Sur un cluster GKE en mode Autopilot, par exemple, leur utilisation affecte la facturation : chaque nœud est entièrement facturé, ce qui peut rapidement annuler les économies espérées sur les coûts d’infrastructure. De plus, chaque Compute Class doit être associée à un Node Pool spécifique. Si les exigences des workloads varient (par exemple, plusieurs configurations de CPU/RAM), il peut être nécessaire de gérer de multiples Node Pools, ce qui complexifie la gestion opérationnelle et la scalabilité du cluster.
Ces limites impliquent que, bien que les Compute Classes soient puissantes, il est important de planifier leur utilisation de façon stratégique, en particulier pour des clusters Autopilot où les optimisations de coûts doivent être soigneusement surveillées.
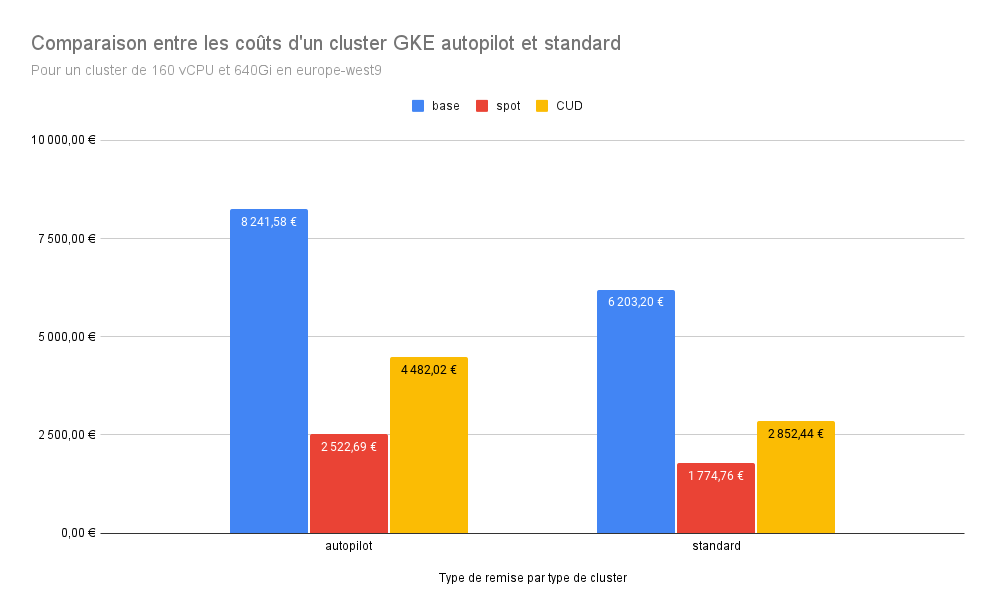
5. Analyse des coûts d’un Cluster GKE Autopilot vs Standard
Pour évaluer l’optimisation de coûts sur GKE, nous comparons un cluster de 160 vCPU et 640 GiB de RAM en région europe-west9 sous deux modes : Autopilot et Standard. Ces deux options ont des modèles de facturation et d’infrastructure différents, avec des variations de coût significatives selon le type de machine utilisé.
| Coût mensuel (€) | Autopilot | Standard |
|---|---|---|
| Base | 8 241,58 | 6 203,20 |
| Spot | 2 522,69 | 1 774,76 |
| CUD | 4 482,02 | 2 852,44 |
-
Base : Ce coût représente l’utilisation du cluster sans réduction, en tarif à la demande (on-demand), où l’Autopilot facture la gestion complète de l’infrastructure en s’occupant du dimensionnement, de la résilience, et des optimisations automatiques. En mode Standard, le coût est moindre, car l’utilisateur gère les configurations et maintenances des nœuds, mais ce mode exige un suivi constant pour maximiser les performances et la stabilité du cluster.
-
Spot : Les VM spot, ou VM préemptibles, permettent une réduction des coûts grâce à leur tarification inférieure. Dans ce cas, le mode Autopilot propose des économies notables, mais le cluster standard reste plus économique, car il n’intègre pas les frais supplémentaires associés à la gestion complète de la plateforme.
-
CUD (Committed Use Discounts) : Les CUD sont des réductions basées sur un engagement de durée d’utilisation, ici appliquées sur une période de trois ans. Ce modèle réduit les coûts pour les deux configurations, mais on observe encore que le mode Standard reste plus avantageux en termes de coût, même avec les engagements.
L’analyse montre que le mode Standard est plus économique dans tous les scénarios, que ce soit en coût à la demande, sur des VM spot, ou avec un engagement CUD. L’Autopilot est avantageux pour les équipes cherchant une gestion simplifiée, avec des services intégrés pour une stabilité optimale du cluster, sans gestion opérationnelle lourde. Cependant, cette approche a un coût, et l’utilisateur doit évaluer si la gestion autonome du mode Standard pourrait compenser cette différence.
Le passage au mode Standard implique principalement une gestion utilisateur des node pools du cluster. Etant donné qu'avec l'autoscaling, la gestion du nombre de noeuds par node pool est simplifié alors la charge de travail est plutôt négligeable. Ajouté à cela l'utilisation des Custom Compute Classes et une gestion maîtrisée des requests de vos charges de travail : le mode Standard est le plus économique.
Le mode Autopilot peut rester avantageux pour de petits clusters avec peu de pods : cela limite la maintenance et permet de ne payer qu'une partie des machines utilisées.
Conclusion
Optimiser les coûts Kubernetes sur GCP est un processus continu qui nécessite une surveillance et des ajustements réguliers pour s’adapter aux variations de la demande. En appliquant ces stratégies, les équipes peuvent mieux contrôler leurs dépenses, maximiser leurs ressources et ainsi améliorer l’efficacité de leurs clusters.